












Everybody knows it: wastewater smells, it is infectious, it is bad. Sewers are even worse, buried in the ground, extremely harsh environments for man and his machines. But, believe it or not, the worst are monitoring data from sewer systems. Although basic data checks (Becouze-Lareure et al., 2012; DWA, 2011) have been suggested, they are not routinely applied. Consequently, data of unknown quality levels pile up and weaken the horrible reputation even more. Sceptical? An in-depth analysis of data submitted for compliance assessment of urban drainage systems in Germany found that about a third of the ca. 300 datasets failed basic plausibility checks (Dittmer et al., 2015).
As we were facing similar data quality issues in our real-world lab “Urban Water Observatory” (UWO) we called recent machine learning methods to the rescue (Figure 1, left) (Disch and Blumensaat, 2019). However, methods such as Support vector machines and Autoencoders, did not really outperform much simpler ARIMA approaches in detecting anomalies in the time series data. And this although these methods usually excel in finding anomalies in large datasets, even invisible watermarks in images (Zhao et al., 2023). In our case, unless the UWO data were heavily preprocessed, denoised, smoothed and imputed with expert knowledge, all methods performed surprisingly bad. But how can one get such high-quality, nicely annotated monitoring data from sewers?
For every-day images of cats, busses and dogs, crowdsourcing is the go-to method to annotate thousands and thousands of images which can then be used to train and optimize classifiers. This also seems to work well for special tasks, such as plants/botany (Goëau et al., 2011), text snippets, etc. and it is no surprise that by typing captchas, you are actually creating ground truth data to help train machine learning models (Yennhi95zz, 2023).
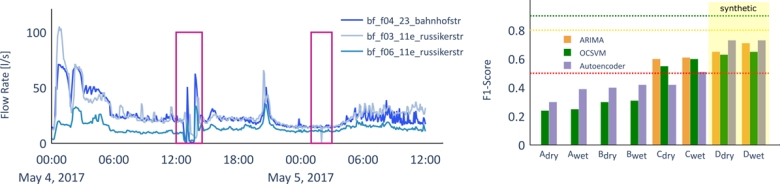
Figure 1, left: Potential anomalies detected show the benefit of using multiple sensors. On the left, variability is captured by all sensors, while on the right, it's only detected by one. Right: F1 scores from Disch and Blumensaat (2019) for different pre-processing methods (A-D) show medium quality between 0.5-0.8, good at 0.8-0.9, and excellent above 0.9. For real data (A-C), performance improves with more pre-processing, with ARIMA performing best. The Autoencoder struggles to match synthetic data performance (D).
But for sewers? Would it even be possible to use crowdsourcing methods, the so-called artificial artificial intelligence, on such special data as sewer water levels and flows? To tackle this question, we initiated a small internal annotation project within our research group (Rieckermann and Disch, 2024). Using the same dataset from our machine learning trials, we shifted the task from machine-detected synthetic anomalies to relying solely on our expertise as sewer researchers. And yes, while we're not spending all our time scanning for anomalies like the Nebuchadnezzar crew monitors the Matrix’s streaming data, we can easily spot a frozen water level sensor when a time series flattens. We've also developed a sharp eye for detecting abnormal fluctuations. It’s as good as it gets—the best game in town.
We gathered 7 time series of sewer flows from various locations in the UWO, refined the machine learning trial scripts, and quickly developed some Python scripts to allow everyone to upload their annotated data into a shared database. To evaluate our annotation skills, we chose the F1 criterion, as in the previous study, which combines the hit rate (precision) and accuracy (recall) of the analyst.
First lesson: before we got any results, we had to go back to start and re-design the tool we used for annotation. We included the ability to visualize multiple time series of nearby sensors at the same time, because we found that it was much more difficult to interpret a single time series alone (Fig 1, left). Also, analysts wanted to see the natural variability during several days while annotating.
Second lesson: our results were sobering. On average, we got mediocre scores in the range of 0.6 -0.7 (Fig. 2, right). On the one hand, this is rather mediocre regarding the best scores of the machine learning tools mentioned above (ARIMA: 0.9-0.8). On the other hand, the good performance of the machine learning models was only possible using pre-processed and annotated data. On raw data the score also dropped to around 0.4-0.5.
Third, we believe that the performance is rather low because, i) flows in small sewers vary a lot, not only during wet periods, but also during dry weather, ii) the raw data were very noisy, iii) the annotation tool was limiting and, most interestingly, iv) we analysts had very different mental models regarding anomalies and how to label the data.
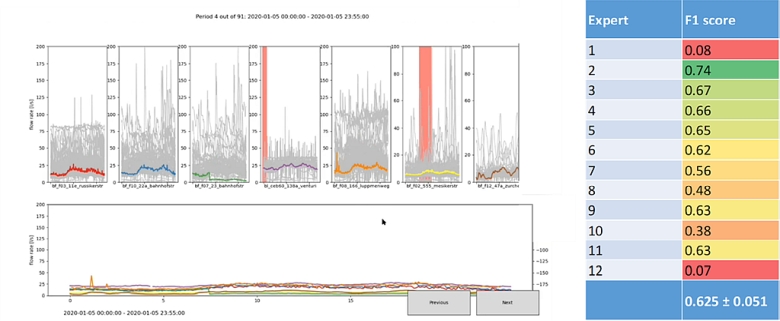
Figure 2, left: Screenshot of our custom annotation tool. Advantages are that the analyst can see related times and at a glance assess the typical variability. Right: F1 scores from our annotation exercise, which are rather mediocre. We believe that the performance is rather low because, i) flows in small sewers vary a lot, not only during wet periods, but also during dry weather, ii) the raw data were very noisy, iii) we analysts had very different mental models regarding anomalies and how to label the data, iv) the annotation tool was limiting.
In summary, while we see a lot of potential for data-driven modeling, or machine learning, in urban drainage research, we agree with others (Eggimann et al., 2017; Fu et al., 2024) that one challenge in our field is missing training datasets. Unfortunately, our results suggest that, unlike images of cats or busses, urban drainage data are not particularly suited to obtain annotations from crowdsourcing. One way forward might be standards for annotations, community actions on artificial artifical intelligence, similar to the “battle of the water networks” (Marchi et al., 2014), and, most of all, role model utilities, such as the one in Fehraltorf, Switzerland, which provide open access to their routine wastewater datasets from sewer systems. Even if they are not perfect.
Oh, and just one more thing… Do you know a good labelling tool for urban drainage time series data? Are you the role model utility which shares their data? Get in touch with us or the CoUDLabs project.
References
- Becouze-Lareure, C., Bazin, C., Namour, P., Breil, P., Perrodin, Y., 2012. Multi-Level Approach of the Ecotoxicological Impact of a Combined Sewer Overflow on a Peri-Urban Stream. J. Water Resour. Prot. 4, 984–992. doi.org/10.4236/jwarp.2012.411114
- Disch, A., Blumensaat, F., 2019. Messfehler oder Prozessanomalie? – Echtzeit-Datenvalidierung für eine zuverlässige Prozessüberwachung in Kanalnetzen. Presented at the Aqua Urbanica 2019: Regenwasser weiterdenken - Bemessen trifft Gestalten, Rigi Kaltbad.
- Dittmer, U., Alber, P., Seller, C., Lieb, W., 2015. Kenngrössen für die Bewertung des Betriebes von Regenüberlaufbecken. Presented at the Jahrestagung der Lehrer und Obleute der Kläranlagen- und Kanal-Nachbarschaften des DWA-Landesverbands Baden-Württemberg am 25./26. März 2015.
- DWA, 2011. DWA-M 181 -Messung von Wasserstand und Durchfluss in Entwässerungssystemen.
- Eggimann, S., Mutzner, L., Wani, O., Schneider, M.Y., Spuhler, D., Moy de Vitry, M., Beutler, P., Maurer, M., 2017. The Potential of Knowing More: A Review of Data-Driven Urban Water Management. Environ. Sci. Technol. 51, 2538–2553. doi.org/10.1021/acs.est.6b04267
- Fu, G., Savic, D., Butler, D., 2024. Making Waves: Towards data-centric water engineering. Water Res. 256, 121585. doi.org/10.1016/j.watres.2024.121585
- Goëau, H., Joly, A., Selmi, S., Bonnet, P., Mouysset, E., Joyeux, L., Molino, J.-F., Birnbaum, P., Bathelemy, D., Boujemaa, N., 2011. Visual-based plant species identification from crowdsourced data, in: Proceedings of the 19th ACM International Conference on Multimedia, MM ’11. Association for Computing Machinery, New York, NY, USA, pp. 813–814. doi.org/10.1145/2072298.2072472
- Marchi, A., Salomons, E., Ostfeld, A., Kapelan, Z., Simpson, A.R., Zecchin, A.C., Maier, H.R., Wu, Z.Y., Elsayed, S.M., Song, Y., Walski, T., Stokes, C., Wu, W., Dandy, G.C., Alvisi, S., Creaco, E., Franchini, M., Saldarriaga, J., Páez, D., Hernández, D., Bohórquez, J., Bent, R., Coffrin, C., Judi, D., McPherson, T., van Hentenryck, P., Matos, J.P., Monteiro, A.J., Matias, N., Yoo, D.G., Lee, H.M., Kim, J.H., Iglesias-Rey, P.L., Martínez-Solano, F.J., Mora-Meliá, D., Ribelles-Aguilar, J.V., Guidolin, M., Fu, G., Reed, P., Wang, Q., Liu, H., McClymont, K., Johns, M., Keedwell, E., Kandiah, V., Jasper, M.N., Drake, K., Shafiee, E., Barandouzi, M.A., Berglund, A.D., Brill, D., Mahinthakumar, G., Ranjithan, R., Zechman, E.M., Morley, M.S., Tricarico, C., de Marinis, G., Tolson, B.A., Khedr, A., Asadzadeh, M., 2014. Battle of the Water Networks II. J. Water Resour. Plan. Manag. 140, 04014009. doi.org/10.1061/(ASCE)WR.1943-5452.0000378
- Rieckermann, J., Disch, A., 2024. Challenges and Prospects in Anomaly Detection of Sewer Monitoring Data: Annotating Synthetic Sewer Data with Known Sensor Failures. https://doi.org/10.31224/3520
- Yennhi95zz, 2023. How Google Trains AI with Your Help through CAPTCHA. Medium. URL https://medium.com/@yennhi95zz/how-google-trains-ai-with-your-help-through-captcha-876cb4eb4d01 (accessed 10.24.24).
- Zhao, X., Zhang, K., Su, Z., Vasan, S., Grishchenko, I., Kruegel, C., Vigna, G., Wang, Y.-X., Li, L., 2023. Invisible Image Watermarks Are Provably Removable Using Generative AI. doi.org/10.48550/arXiv.2306.01953
0 Comments
No comments found!